How Photonic Processors Will Save Machine Learning
How Photonic Processors Will Save Machine Learning
a quick introduction of LightOn’s OPU
Machine learning is expensive — it requires high computing capacity. For example, training of the OpenAI’s famous GPT-3 model would cost over $4.5M, and requires an amount of energy equivalent to the yearly consumption of 126 Danish homes and creates a carbon footprint equivalent to traveling 700,000 kilometers by car for a single training session.
Photonic processors are one of the most promising solutions to the huge computing capacity need and the extreme carbon footprint because they are fast (as we know, light is the fastest thing in the universe) and really energy efficient.
Some companies on the market have production-ready photonic processors. One of my favorites is LightOn because their solution is relatively simple, and the way it works is something like magic (you will see why).
LightOn’s OPU (Optical Processing Unit) can do only one thing, but it can do this one thing fast and efficiently. It can multiply a vector with a giant random matrix. The hardware converts the input to a light pattern. A special waveguide does the random matrix multiplication in an analog way. In the end, a camera converts back the result to a vector. The random matrix is fixed, so the multiplication hardware (the waveguide) here is a passive element. But how can help a random matrix multiplicator to machine learning?
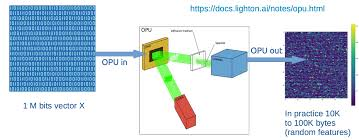
Multiplication with a fixed giant random matrix sounds meaningless, but don’t listen to your intuition, it is a very meaningful thing. It is a convenient way for dimension reduction called random projection. The random projection has a good property; it nearly preserves the distances because of the Johnson–Lindenstrauss lemma. So if you have two vectors in a high dimensional space, the distance of the projected vectors will be nearly the same as their original distance.
This distance preserving property can be used very well in reinforcement learning. In LightOn’s example, they are using their OPU to convert the actual game state to a 32 dimension vector. Here the game state is a screen snapshot that is represented by a 33600 (210x160 pixels) vector — the OPU projects from this 33600 dimension space to a 32 dimension space. The learning method is simple Q-learning. The algorithm calculates the Q value and stores it for the (projected) state. If the Q value is unknown, it uses the Q value of the 9 nearest neighbors and calculates the average of them. Because of the Johnson–Lindenstrauss lemma, the distance of the projected vectors is more or less the same as the original state vectors, so the K nearest neighbors of the projected vector are projected from near original vectors. In this case, OPU is used to reduce the dimensions to create an easier problem (a 32 dimension vector is better than a 33600 dimension) which needs less storage, less computing capacity, or a smaller neural network. The same method can be used in recommender systems or any other cases where dimension reduction can be used, and the OPU does it fast on really high dimensional vectors. You can find the code here.
As you can see, the method works fine:
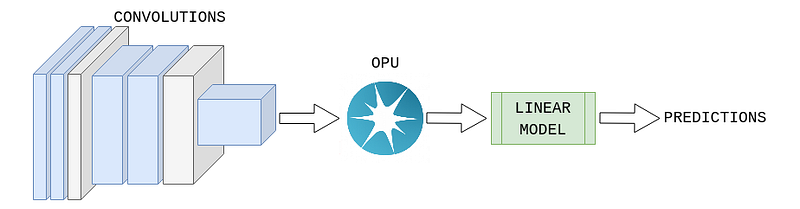
Another use case, when OPU is used to project from a low dimensional space to a high dimensional space. In LightOn’s transfer learning example, OPU is used instead of the linear layers of a neural network. In this case, a pretrained CNN (VGG, ResNet, etc.) is used for feature extraction, but the classification is not done by a neural network. Instead of the dense layers, OPU is projecting the feature vector to a high dimensional space where the samples are linearly separable. So, thanks to OPU a simple linear classifier can be used instead of a neural network.
The above 2 examples used the OPU to map the original problem to an easier problem that needs less computing capacity and storage, but can it be used to make the neural network training process easier? The answer is yes. There is a method called Direct Feedback Alignment in this case the error is propagated through fixed random feedback connections directly from the output layer to each hidden layer. This method has 2 advantages. We can train the hidden layers parallelly and the error is propagated through a fixed random matrix what can be done efficiently with the OPU. Using random matrices instead of backpropagation sounds like magic, but it works.
Here is a nice YouTube video about DFA:
As you saw, a relatively simple photonic hardware can help multiple ways to reduce the huge computing capacity needs of machine learning, and OPU is only one of the photonic hardware on the market. There are other solutions with programable matrices or quantum photonic solutions. It is worth keeping your eyes on this field because machine learning needs more and more computing capacity, and photonic processors are one of the most promising ways to provide this.