Tensorflow alapozó 4.
Tensorflow alapozó 4.
(Reinforcement learning, Deep Q-learning és OpenAI Gym)
Annak idején bejárta a tech sajtót a hír, hogy a Google által felvásárolt DeepMind olyan mesterséges intelligenciát fejlesztett, ami pusztán a képernyő figyelésével képes volt megtanulni Atari játékokat játszani.
Annak ellenére, hogy a dolog baromi izgalmas, azért felmerül az emberben a kérdés, hogy miért vásárol fel a Google fél milliárd dollárért egy céget, ahol retro játékokhoz készítenek mesterséges intelligenciát? Nos, egy rendszer, ami képes megtanulni retro játékokat játszani, ugyanúgy képes lehet elvezérelni egy robotot is ami mondjuk homokzsákokat pakol árvíz idején, vagy éppen embereket ment ki egy földrengés helyszínéről.
A DeepMind által használt technikát Deep Q-learningnek nevezik, és a reinforcement learning (megerősítéses tanulás) egy formája.

Akármi is legyen a konkrét feladat, minden esetben ráhúzható a fenti képen látható modell. Minden esetben van valamilyen környezet (environment), amiben a robotunk (agent) létezik. Ez lehet egy számítógépes játék egyszerű szabályokkal, de lehet akár a valós tér is (aminek működését a fizika szabályai határozzák meg). Ezt a környezetet értelmezi a robot. A környezet absztrakt értelmezése az állapot (state). A robot képes műveleteket (action) végezni, amik hatással vannak a környezetre. Egy számítógépes játék esetén a műveletek száma elég korlátozott (egy Atari játéknál pl. egy joystick mozgatása fel/le/jobbra/balra), míg egy valós robot esetén sokkal többféle mozgás elképzelhető. A művelet elvégzését követően a környezet valahogy változik, amiből újra generálódik az absztrakt állapot (state) és még egy fontos dolog: a jutalom (reward). A jutalom miatt hívjuk ezt a tanulási módszert megerősítéses tanulásnak, hiszen ahogyan az állatok idomítása esetén, itt is a sikeres akciókat jutalmazzuk, a sikerteleneket pedig büntetjük. A robot célja, hogy minél jobban elvégezze a feladatát, tehát minél nagyobb értékben gyűjtsön össze reward-ot (pl. egy számítógépes játék esetén minél több pontot szerezzen).
A DeepMind által használt Deep Q-learning lényege, hogy az aktuális állapot (state) alapján minden egyes művelethez (action) megpróbáljuk megtippelni a összes várható jutalmat (reward), és mindig azt a műveletet választjuk, amelyik a legnagyobb jutalommal kecsegtet. A Q-learningben a Q (quality of action) ezt az elvárható jutalmat jelenti. A játék indulásakor még semmit nem tud a rendszer a Q értékéről, így csak vaktában próbálkozik felderíteni a játékot. Minél tovább játszik, annál több adata lesz arról, hogy melyik akció milyen jutalommal jár, így annál pontosabban tudja megtippelni a Q értékét. Fontos megjegyezni, hogy egy akcióhoz tartozó Q nem az akcióért közvetlenül kapható jutalom értékét jelenti, hanem azt, hogy ha az adott akciót választva végigjátsszuk a játékot, mekkora összes jutalomra számíthatunk. Vegyünk például egy labirintusos játékot, ahol a cél kijutni a labirintusból úgy, hogy eközben a legtöbb kincset szedjük fel. Választanunk kell, hogy jobbra, vagy balra megyünk. Balra van egy kincs, viszont arra nem lehet kijutni a labirintusból. Jobbra nincs semmi, de ha a következő sarkon jobbra fordulunk, akkor kijutunk a labirintusból. Ha csak közvetlenül az akció által elérhető rewardot néznénk, minden esetben balra kellene mennünk, hiszen arra van a kincs (nagyobb reward), míg a jobbra menéssel közvetlenül nem nyerünk semmit (0 reward). Ennek fényében a Q értékét a következőképpen számoljuk ki:
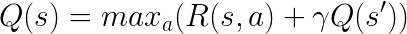
A fenti képletet Bellman egyenletnek hívjuk és valójában nem túl bonyolult. Az s jelenti az állapotot, az a az akciót. Az R(s,a) az adott állapotból adott akcióval elérhető jutalom (reward), a Q(s) pedig az adott állapotból elérhető legnagyobb összes jutalom. Hogy megkapjuk a Q értékét, az aktuális akcióval elérhető jutalomhoz (R(s,a)) adjuk hozzá az akció által előállt következő állapot (s’) várható Q értékét megszorozva egy gamma konstanssal, ami azt jelképezi, hogy a jövőben várható jutalom mennyit ér nekünk a jelenben. Tehát fogjuk az akcióval nyerhető jutalmat, hozzáadjuk a jövőben elvárható jutalom “diszkontált” értékét, és azt az akciót választjuk, ahol ez a legnagyobb. Dióhéjban igazából ennyi a Q-learning lényege. Attól lesz belőle Deep Q-learning, hogy a Q érték megtippelésére neurális hálót használunk.
Mielőtt elkezdenénk kódolni, ismerkedjünk meg az OpenAI Gymmel, ami pont az, amire elsőre gondol az ember: egy edzőterem robotoknak. Kicsit pontosabban: a Gym tulajdonképpen egy szabványos interfész bármilyen környezethez. A programkönyvtár letöltésével eleve kapunk egy csomó környezetet (pl. Atari játékokat), de igény esetén további szimulációs környezetekkel is bővíthető. Vannak olyan környezetek, amelyek komoly fizikai engine-el rendelkeznek, így akár valós robotok szimulált környezetben való tanítására is megfelelőek lehetnek (inkább itt törjünk össze pár robotot a tanítás során, mint a valóságban). Lássuk hogy néz ki mindez a gyakorlatban.
A fenti nagyon egyszerű kód a Breakout nevű Atari játék környezetet tölti be, majd véletlenszerűen játszik 10 000 fordulót. Sok értelme nincs, viszont szépen láthatjuk, hogyan működik a Gym. A 3. sorban inicializáljuk a környezetet. Itt adjuk meg, hogy a Breakout játékkal szeretnénk játszani. Az elérhető környezetek listája itt található. A 4. sorban alapállapotba hozzuk a környezetet a reset függvénnyel. A függvény visszatérési értéke egy observation tenzor, ami egy pillanatkép a környezet aktuális állapotáról. Ez lehet valami előemésztett dolog, pl. a labda helyzete és sebességvektora, de lehet simán egy képernyőkép is, mint a DeepMind esetén. Hogy pontosan milyen az observation tenzor szerkezete, az a környezettől függ. Az env.render() megjeleníti a környezet aktuális állapotát, így szemmel is követhetjük a történéseket. Az env.action_space változóban kérhetjük el a környezetben végezhető akciókat, a sample függvény pedig rögtön választ is egyet közölük véletlenszerűen, megspórolva nekünk pár sor kódot. Az env.step függvény alkalmazza az akciót a környezetre, amitől az meg fog változni. A függvény visszatérési értéke a megváltozott környezetről egy új pillanatkép (observation), az akcióért kapott közvetlen jutalom (reward), egy boolean változó, ami azt jelzi, hogy véget ért a játék (done), és némi kiegészítő infó (info). Az utolsó előtti pár sorban ellenőrizzük a done változó értékét, és ha véget ért a játék, alap állapotba hozzuk a környezetet (reset). Ennyi igazából elég is a Gym-ről. Jöhet az igazi kódolás.
Ha nincs még tapasztalatod a Tensorflow-val, érdemes elolvasni a cikksorozat első részét:
A Gym-ben elérhető egyik legegyszerűbb játék a CartPole, ahol egy kis virtuális kocsit kell vezérelnünk, ami egy botot egyensúlyoz. Az ehhez tartozó Gym-es animáció elég sután néz ki, így inkább nézzünk egy videót arról, ahogyan egy igazi robot csinálja ugyanezt a betanított algoritmus segítségével.
Szóval a cél a fenti robot betanítása, hogy minél tovább képes legyen egyensúlyozni a bottal. Az alábbi kód az én megvalósításom, amit pár másik kódból lapátoltam össze. A kód elérhető Google Colabban is, így aki akarja, rögtön ki is próbálhatja.
A kód elején inicializálunk pár konstanst a Q-learninghez, majd inicializáljuk a Gym-et és lekérdezzük az observation valamint az action tenzor méretét. A játék tenzorainak részletes leírása itt található a játék forráskódjával együtt. Az observation tenzor a CartPole esetén egy 4 elemű vektor. Az első elem az autó helyzetét adja meg, a második az autó sebességét, a harmadik elem a bot dőlésszöge, míg a negyedik a bot dőlésének sebessége. Ez alapján kell nekünk két akció közül választani. Az egyik akció a kocsi jobbra mozgatása, a másik a balra mozgatás. A játék akkor ér véget, ha a bot dőlésszöge 12 foknál nagyobb, vagy sikerült 200 lépésen keresztül egyensúlyozni a botot. A tanításhoz a következő egyszerű hálózatot fogjuk használni:
model = Sequential()
model.add(Dense(16, input_shape=(observation_space_size, ), activation='relu'))
model.add(Dense(16, activation='relu'))
model.add(Dense(action_space_size, activation='linear'))
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_6 (Dense) (None, 16) 80
_________________________________________________________________
dense_7 (Dense) (None, 16) 272
_________________________________________________________________
dense_8 (Dense) (None, 2) 34
=================================================================
Total params: 386
Trainable params: 386
Non-trainable params: 0
_________________________________________________________________
A hálózat 3 rétegből áll. Az első teljesen huzalozott réteg 4 bemenettel rendelkezik (ekkora az aktuális állapotot leíró observation tenzor mérete), amit 16 kimenetre képez le. A következő réteg egy 16 bemenettel és 16 kimenettel rendelkező teljesen huzalozott réteg, míg az utolsó réteg a 16 bemenetet képzi le 2 kimenetre, ami az adott akciókhoz (jobbra/balra mozgás) tartozó Q érték. Ez összesen 386 állítható paramétert fog jelenteni.
model.compile(loss=”mse”, optimizer=Adam(lr=LEARNING_RATE))
A modell optimalizálásához a szokásos Adam-et fogjuk használni, hibafüggvénynek pedig a négyzetes hibák átlagát (mean squared error), mivel a konkrét Q értékek betanítása a cél.
Maga a program 2 egymásba ágyazott ciklusból áll. A külső ciklusban futtatjuk a játékokat, a belső ciklus pedig egy játék végigjátszása. Ennek megfelelőn a belső ciklus mindig akkor ér véget, ha az env.step metódus játék végét jelző done visszaadott értéke igaz.
A belső ciklus elején található kódblokk határozza meg a következő akciót.
if np.random.rand() < exploration_rate:
action = random.randrange(action_space_size)
else:
state = np.reshape(observation, [1, observation_space_size])
q_values = model.predict(state)
action = np.argmax(q_values[0])
Itt kezdjünk az else ággal, amiben a hálózat által tippelt Q érték alapján megyünk tovább. Az első sor megfelelő formába hozza az observation vektort, a neurális háló ugyanis [batch, input] formában várja a bemeneteket. A predict függvénnyel futtatjuk a hálózatot, majd az argmax-al meghatározzuk a nagyobb Q értékhez tartozó akciót.
Mivel kezdetben semmit nem tudunk a környezetről, ezért véletlenszerűen választunk a lehetséges lépések között. Ehhez bevezetünk egy exploration_rate változót, ami azt mondja meg, hogy a következő lépésben milyen valószínűséggel választunk véletlen akciót (felfedezünk) ahelyett, hogy a tippelt Q értéknek megfelelően mennénk tovább. Az exploration_rate-et minden lépésben csökkentjük, így minél okosabb a hálózat, annál inkább a tippelt Q értékekre hagyatkozunk a véletlen választás helyett. Érdemes definiálni egy minimális exploration_rate értéket, hogy mindig legyen véletlen próbálkozás, ezzel elkerülve hogy lokális optimumokban elakadjon az algoritmus. Felmerülhet a kérdés, hogy ha úgyis véletlen súlyokkal inicializáljuk a hálózatot, miért nem elég simán a tippelt Q értékre támaszkodni, ami a futások elején valamilyen véletlen függvénye az állapotnak? Ezzel az a baj, hogy ahogy tanul a rendszer hamar megtanulja, hogy merre vannak reward-ok, és mindig afelé menne. Emlékezzünk vissza a labirintusos példára. Ha balra van egy kincs, jobbra viszont nincs semmi, viszont jobbra van a kijárat, akkor egy hálózat ami rátalált a kincsre, soha nem indulna meg jobbra, így a rendszer elakadna egy lokális optimumban. Azzal, hogy bevezetjük az exploration_rate-et és a véletlen lépéseket, “ki tudjuk rázni” a rendszert az ilyen lokális optimumokból.
observation_next, reward, done, info = env.step(action)
reward = reward if not done else -200
memory.append((observation, action, reward, observation_next, done))
observation = observation_next
A középső blokkban alkalmazzuk az akciót a környezetre, majd egy memóriában letároljuk az adatokat, vagyis azt, hogy milyen állapotból milyen akcióval milyen állapotba jutottunk el. Ez később a tanulásnál lesz érdekes.
Az utolsó blokk a tanulás, ami az egyes játékok végén történik, és ami tulajdonképpen az egész rendszer esszenciája.
state_batch, qvalue_batch = [], []
batch = random.sample(memory, BATCH_SIZE)
for observation, action, reward, observation_next, done in batch:
q_update = reward
if not done:
state_next = np.reshape(observation_next, [1, observation_space_size])
q_predicted = np.amax(model.predict(state_next)[0])
q_update = reward + (GAMMA * q_predicted)
state = np.reshape(observation, [1, observation_space_size])
q_values = model.predict(state)
q_values[0][action] = q_update
state_batch.append(state[0])
qvalue_batch.append(q_values[0])
model.fit(np.array(state_batch), np.array(qvalue_batch), batch_size=len(state_batch), epochs=1, verbose=0)
A kód elején véletlenszerűen kiválasztunk pár mintát a memóriából (ezek mennyisége a BATCH_SIZE konstansban van definiálva). Ezekkel a mintákkal fogjuk az adott fordulóban tanítani a hálózatot. A q_update mezőbe kerül a Q érték, ami végállapot esetén megegyezik a reward-al, más esetben pedig a Bellman egyenletnek megfelelően számoljuk. Ez utóbbi esetben tehát fogjuk a rewardot, majd hozzáadjuk a modellünk által tippelt Q érték GAMMA szorosát. A következő pár sorban lefuttatjuk a hálózatunkat a memóriában szereplő állapotra, majd a memóriában szereplő akcióhoz tartozó Q értéket frissítjük a most számolttal. A state-eket és az akciókhoz számolt Q értékeket egy batch-be pakoljuk, majd egyben betanítjuk a hálózatnak. Lényegében ennyi a Q-learning. Minden körben választunk pár mintát a memóriából, a memória alapján újraszámoljuk a Q értékeket, majd betanítjuk a hálózatnak, egészen addig, míg a hálózat nem lesz elég pontos. A fenti kódot Colabban futtatva nekem olyan 7000 iteráció után állt be konstansan a maximális 200 pontra, de addig is szépen látszik az emelkedés a számokban (amik azt jelentik, hogy hány lépésen keresztül sikerült egyensúlyozni a botot).
Sokan csalódottak lehetnek, hisz a cikk elején Atari játékokat játszó MI-ről írtam, erre kaptak egy vacak botot egyensúlyozó robotot. A helyzet azonban az, hogy valójában Atari játékokat játszani sem sokkal bonyolultabb. Akit érdekel a konkrét megvalósítás, az itt megtalálja a forráskódot. Gyorsan szaladjunk is végig a főbb részeken és különbségeken.
Nyilván az egyik különbség maga a hálózat, amit a convolutional_neural_network.py állományban találunk. Igazából nem sokban különbözik a mi botos megoldásunktól. A mi megoldásunk egy 3 rétegű teljesen huzalozott hálózat, aminek a bemenete a kocsi és a bot helyzete valamint sebessége. Mivel az Atari játékoknál a bemenet egy pixeles kép, ezért a helyzetet és sebesség adatokat is a hálózatnak kell kinyernie. Ehhez a fenti példában (és a DeepMind megoldásában is) egy 3 rétegű konvolúciós hálót használnak. Tehát ez a hálózat mindössze abban különbözik a mi hálózatunktól, hogy az elejére raktak pár konvolúciós réteget a szükséges adatok kinyerésére, amit a cartpole-os játék esetén mi készen kaptunk.
Persze a dolog azért nem ennyire egyszerű. Ha megnézünk egy képkockát a Breakout játékból (pl. azt ami a cikk elején található), rájöhetünk, hogy ebből nem fogjuk megtudni sem a labda mozgásának irányát, sem annak sebességét. Ahhoz, hogy ezeket meghatározhassuk, több képkockára van szükség. A Gym-es Breakout esetén az observation tenzor 250x160x3-as méretű és olyan szerkezetű, mint amit a cikksorozat első részében a CIFAR10-es képek kódolására használtunk. Ekkora képre nincs szükség (kisebb monitoron is lehet Breakout-ot játszani), ráadásul a színeknek sincs jelentősége (fekete-fehér monitoron is lehet Breakout-ot játszani). Éppen ezért első körben a képet 84x84x1-es szürke árnyalatos tenzorokká konvertálják, majd ezekből összerakják az aktuális és az azt megelőző három fázis képkockáit. Végül az így kapott 84x84x4-es tenzorok képzik majd a konvolúciós háló bemenetét, amiből már kinyerhető minden szükséges adat. Ezt a fenti program a gym_wrappers.py-ben található csomagoló osztállyal oldja meg, aminek eredményeként a gym környezet által visszaadott observation tenzor már a kívánt 84x84x4-es formában fog jönni.
Van egy harmadik trükk is. A tanítás folyamán a program két ugyanolyan szerkezetű hálózatot használ. Egyet a Q értékek tippeléséhez (target network) és egyet a tanításhoz. A tanítás során módosult hálózat alapján néha frissítjük a target networkot is, de nem minden körben. Ezzel a trükkel hatékonyabbá tehető a tanítás, amit a ddqn_game_model.py-ban található DDQNSolver osztály valósít meg.
Igazából ez a 3 főbb dolog az, amiben a fenti (univerzális!) Atari játékokat játszani képes program a mi primitív bot egyensúlyozó robotunktól küölnbözik.
Körülbelül ennyit szerettem volna írni a Q-learningről és a megerősítéses tanulásról. Fontos megjegyezni, hogy a deep reinfocement learning egy igen forró terület. Naponta jönnek ki publikációk, új topológiák és új algoritmusok. Némelyikük a Q-learning valamilyen módosított változata, míg mások ettől eltérő módon működnek. Azt gondolom, hogy a fenti írás jó kiinduló alap lehet bárkinek. Akit pedig mélyebben érdekel a téma, az az Interneten rengeteg anyagot találhat a továbblépéshez.
UPDATE: Tensorflow-hoz készült egy Tensorflow Agents nevű programkönyvtár, ami reinforcement learninghez tartalmaz mindenféle okosságot valamint az ismertebb módszerek implementációját, így akit mélyebben érdekel a téma, mindenképpen látogasson el a projekt oldalára.
Ha tetszett az írás, olvasd el az előző részeket is:
(autoencoderek, word2vec és embedding avagy dimenzió redukció neurális hálókkal)medium.com
A következő rész pedig itt érhető el: